Mám tu před sebou projekt v PHP, který je potřeba zrychlit – TTFB je moc velký. Mým úkolem je zjistit, kde je problém a jak projekt zrychlit. V článku se budu snažit popsat, jak jsem postupoval a jaké jsem použil nástroje.
Projekt
Aplikace je napsána v Symfony s nějakými custom úpravami. Používá vlastní ORM framework, ke kterému není dokumentace. Ve vývojovém režimu v debug baru nejsou vidět SQL dotazy, které se na databázi posílají. Není se moc čeho chytit.
Ze zkušenosti vím, že často bývá úzkým hrdlem práce s databází – indexy, časté dotazování, zbytečně rozsáhlé výsledky selectů, které se pak zpracovávají až v PHP… .
Projekt jsem si spustil lokálně v Dockeru a vyzkoušel si dvě různé verze databáze a také dvě různá místa, kde jsou data uložena. Jedno je můj domácí server s klasickými HDD, druhé je na mnohem lepším stroji s SSD disky, ale přístupný přes Internet.
Případná vylepšení budou více patrná než, když budou data v docker containeru na mém lokálním stroji.
Jak na to?
Nejprve potřebuji zjistit, co se do databáze vlastně posílá. Mám více možností:
- The General Log – nastavit MySQL tak, aby logovala všechny dotazy, které do databáze chodí https://dev.mysql.com/doc/refman/8.0/en/query-log.html
- upravit si ORM, aby se ukládaly všechny dotazy, které se do databáze posílají
- použít pt-query-digest – https://docs.percona.com/percona-toolkit/pt-query-digest.html
První možnost není špatná, jen dostanu spousty dotazů, kterými se budu muset prokousat, zjistit kolikrát se který zavolá a jak dlouho to trvá. Navíc budu muset měnit konfiguraci databáze.
Druhá možnost je ještě horší, musím se hrabat v kódu frameworku a zkoumat jak přidat logování. Výsledný log bude asi ještě hůře použitelný, dostanu SQL dotazy a k nim zvlášť parametry, ze kterých se dotaz složí.
Naštěstí máme ještě třetí možnost. Zachytit a uložit reálnou komunikaci s databází a na tento log pak použít nástroj pt-query-digest. Pro mne je toho nejjednodušší možnost jak zjistit, kde je problém.
Co je pt-query-digest?
Utilita pt-query-digest je jeden z hromady nástrojů celého balíku Percona Toolkit https://docs.percona.com/percona-toolkit/index.html. Umí analyzovat slow.log, zachycený log z tcpdumpu, binární logy MySQL. Jedná se o velmi mocný nástroj, ze kterého použiju jen velmi malou část jeho funkcionality.
Dokumentace k nástroji je zde: https://docs.percona.com/percona-toolkit/pt-query-digest.html – umí toho opravdu hodně. Dokumentace, ke všem utilitám od Percony, je velmi zajímavé večerní čtení 😀.
Instalace nástrojů
Nástroj pt-query-digest je script napsaný v Perlu. Na MacOS jsem instaloval takto:
wget https://percona.com/get/pt-query-digest
chmod +x pt-query-digestPak stačí spustit:
./pt-query-digest --helpZobrazí se nápověda, nástroj bude fungovat.
V tomto případě chci ale vše dělat rovnou v docker containeru. Nainstaluji si tedy vše do něj.
# zjistím název containeru php aplikace
docker ps
# dostanu se dovnitř
docker exec -it <název containeru> bash
# instalace tcpdumpu a wget
apt update && apt install tcpdump wget -y
# instalace pt-query-digest
mkdir -p /var/www/html/temp
cd /var/www/html/temp
wget https://percona.com/get/pt-query-digest
chmod +x pt-query-digest
# otestování jestli funguje
./pt-query-digest --helpMůj container je založen na Ubuntu, mám tedy vše dostupné rovnou. Pokud máte základ jiný, musíte si instalaci přizpůsobit, případně analýzu zachycené komunikace dělat mimo container.
Analýza
V docker containeru spustím tcpdump, kterým zachytím komunikaci s databází.
tcpdump -s 65535 -x -nn -q -tttt -i any -c 100000 port 3306 > mysql.tcp.txtZajímavý je hlavně parametr:
-cpočet zachycených packetů
Schválně dávám vysoké číslo, aby tcpdump zachytil veškerou komunikaci na portu 3306 a nic nezahodil.
Po spuštění tcpdump udělám v prohlížeči refresh homepage webu.
Výsledek bude vypadat nějak takto:
root@1fb0a7e6d6f0:/var/www/html/temp# tcpdump -s 65535 -x -nn -q -tttt -i any -c 10000 port 3306 > mysql.tcp.txt
tcpdump: data link type LINUX_SLL2
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on any, link-type LINUX_SLL2 (Linux cooked v2), snapshot length 65535 bytes
1000 packets captured
1124 packets received by filter
47 packets dropped by kernel
root@1fb0a7e6d6f0:/var/www/html/temp#Pokud se tcpdump po načtení stránky neukončí sám, můžete jej ukončit ručně pomocí CTRL+C.
Na disk se komunikace zaznamenala do souboru mysql.tcp.txt.
Pustíme na něj nástroj pt-query-digest a výstup uložíme do souboru:
./pt-query-digest --type tcpdump mysql.tcp.txt > stat.logV souboru stat.log je statistika provedených dotazů. V mém případě několik prvních řádků vypadá takto:
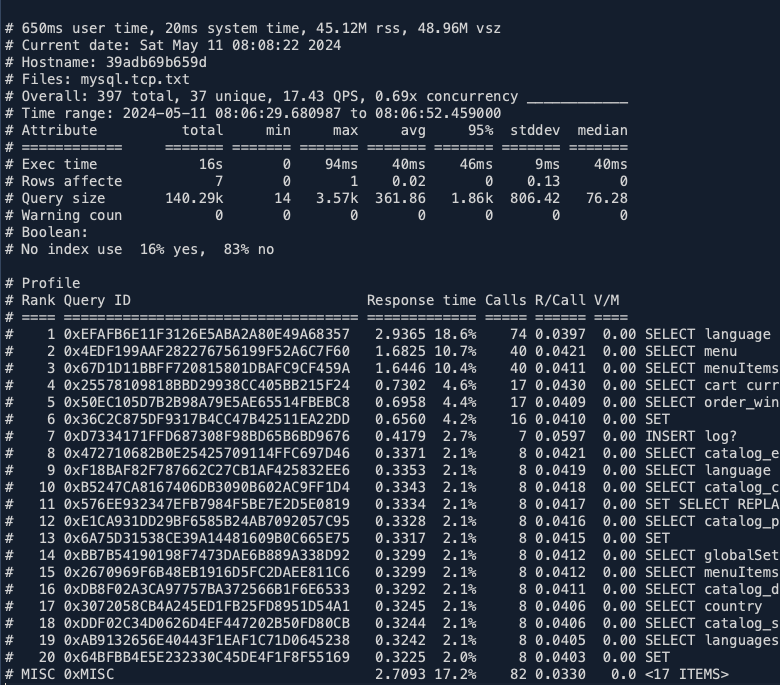
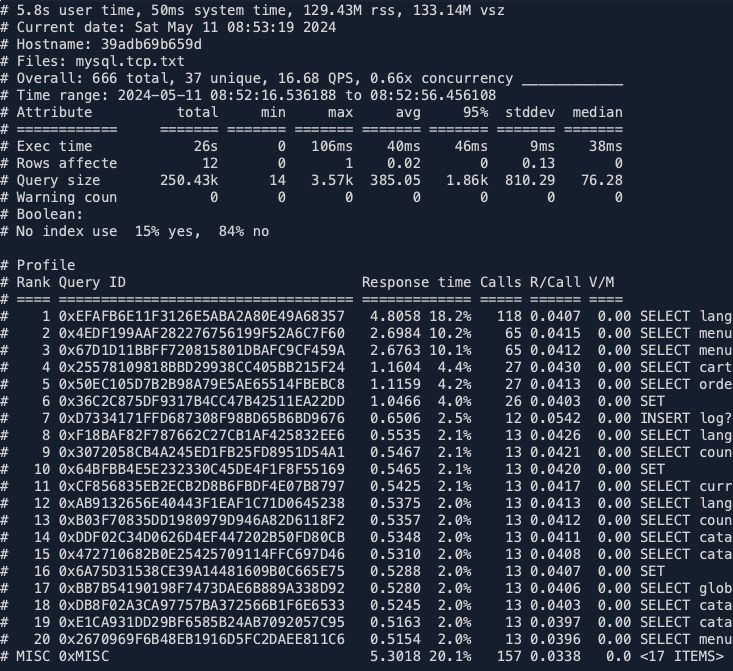
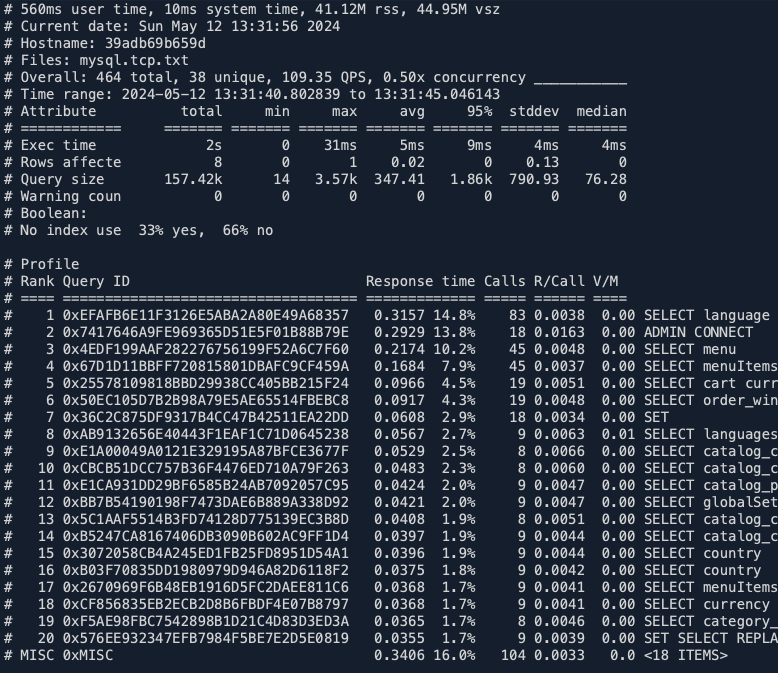
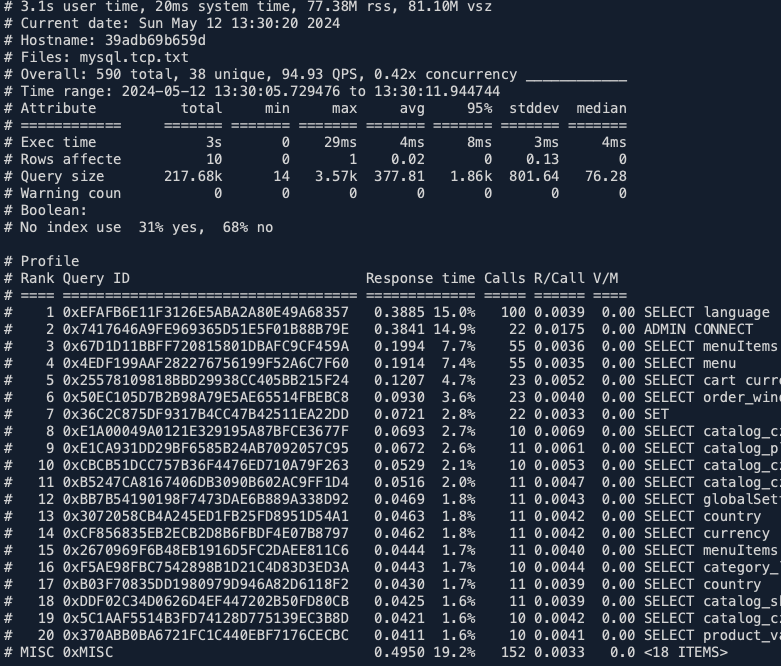
Soubor pokračuje, je rozebrán každý jeden dotaz z celého seznamu a jsou k němu další podrobnosti – jak dlouho trval, použití indexů atd.
Co dál?
Díky logům mám trochu lepší představu, co se v aplikaci děje. Na první pohled mi přijde zvláštních několik věcí:
- počet SQL dotazů na tabulku languages
- počet SQL dotazů na menu
- volání
INSERTs každou návštěvou stránky - jak málo se používají indexy
Tabulka languages je statická, nic se v ní nemění. Měla by jít snad jednoduše cachovat. Stejně tak menu, jen musím dát pozor na jazykové verze.
Volání INSERT opravit půjde taky. Zjistil jsem, že s každou návštěvou se do databáze ukládají stránky, které vrací 404. Jakýkoliv pokus o zobrazení neexistujícího obrázku, test jestli se jedná o WordPress, favicony, cokoliv si představíte, znamená jeden záznam do databáze. V tabulce je skoro 400 tisíc záznamů. Už jen jejím promazáním databázi ulevím.
Indexy musím prozkoumat, projít dotaz po dotazu a zjistit, proč se nepoužívají.
Pokud výše popsané úpravy nebudou stačit, budu muset nainstalovat xdebug a pomocí profileru hledat, kde tráví PHP nejvíce času.
Výsledek?
Zatím žádný nemám 😀. Musím se ponořit do zdrojových kódů – zjistit, proč se tolikrát volá select na tabulku languages, jak výsledek cachovat, jak cachovat menu atd.
Optimalizace se zákazníkovi velice špatně naceňuje, rozptyl je opravdu velký. Mohou to být jednotky hodin až dny. Prvotní zkoumání je hotové za hodinu až dvě. V mém případě to trvalo trochu déle, protože jsem narazil a problém s nástrojem pt-query-digest. Nechtěl mi fungovat s databází, kterou jsem měl k dispozici, musel jsem najít starší verze. Naštěstí mám více strojů s databázemi různých verzí, mohl jsem tedy testovat.
Závěr?
Když PHP aplikaci neznáte, pt-query-digest vám poskytne docela slušný náhled na to, co se v ní, z pohledu databáze, děje. Velkou výhodou je, že nemusíte ani měnit žádné nastavení, prostě si odposlechnete komunikaci se serverem a tu analyzujete.
Ladění výkonu aplikací mě hodně baví. Ponořím se do analýzy, upravuji chování aplikace a měřím dopady svých úprav. U jedné z aplikací jsem tak TTFB srazil z 6s na 1s. Opravdu velké zrychlení. Sice jsem s tím strávil celý víkend, ale rozhodně to stálo za to. Na produkčním hardware zrychlení nebylo tak velké, ale web chodí mnohem lépe, než před optimalizací.
Napsat komentář